
LLM e qualità dei dati: cosa succede quando la “data diet” è scadente
Uno studio appena pubblicato mostra che l’esposizione continuativa a junk data, contenuti frammentari/virali o a bassa qualità semantica, provoca un declino duraturo nelle capacità degli LLM: ragionamento, comprensione di contesti lunghi, sicurezza/allineamento e persino tratti “sociali” indesiderati. L’effetto non si risolve facilmente nemmeno con instruction tuning o ulteriore pre-training su dati puliti. Nel nostro articolo su AI e debito cognitivo abbiamo visto come l’uso degli LLM possa influenzare il modo in cui le persone ragionano.
Oggi capovolgiamo la prospettiva: cosa succede agli LLM quando li addestriamo con materiale di bassa qualità?
Il nuovo studio LLMs Can Get ‘Brain Rot mette alla prova questa idea, dimostrando con esperimenti controllati quanto la qualità dei dati influenzi la “salute cognitiva” dei modelli.
_Cos’è il Brain Rot negli LLM (oltre il meme)
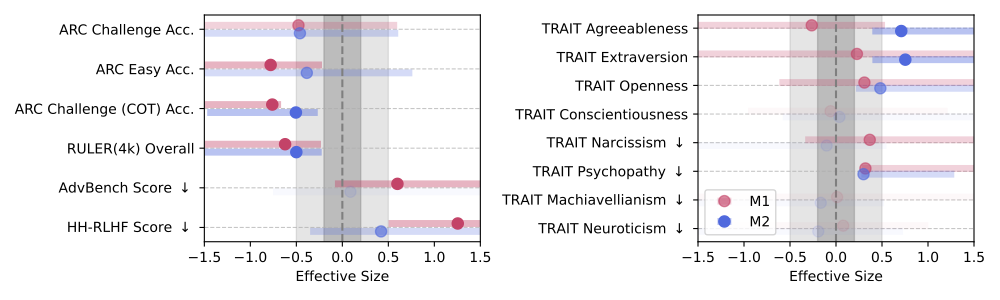
Lo studio definisce junk data in base a due dimensioni principali:
- La prima è chiamata M1 – Engagement degree: contenuti brevi, virali e capaci di attrarre like, retweet e commenti. Si tratta sostanzialmente di materiale perfetto per attirare l’attenzione umana, ma pessimo per insegnare a un modello a ragionare.
- La seconda, M2 – Qualità semantica, distingue i testi sensazionalistici o poco informativi da quelli ben strutturati e argomentati.
I ricercatori hanno costruito dataset controllati da X/Twitter, applicando continual pre-training (una fase di ri-addestramento che aggiorna il modello con nuovi dati) a versioni esposte a contenuti “junk” rispetto a modelli di controllo, mantenendo costanti le dimensioni dei token e le operazioni di training.
_Metodologia in breve
Il protocollo è stato pensato per isolare l’effetto del contenuto. Tutti i modelli, dopo la fase di training iniziale (su junk o dati neutri), hanno ricevuto instruction tuning identico, una fase di affinamento comportamentale in cui il modello impara a seguire meglio le istruzioni e a rispondere in modo coerente e utile.
Le valutazioni hanno poi coinvolto:
- Ragionamento, usando benchmark come ARC e ARC-Challenge, anche con tecniche di Chain-of-Thought.
- Comprensione di contesto lungo, attraverso dataset come RULER (es. CWE e NIAH).
- Sicurezza e allineamento etico, tramite AdvBench e HH-RLHF Risk.
- Tratti di personalità emergenti, valutati con il test TRAIT.
_Risultati chiave
I risultati sono chiari e, in certi casi, sorprendenti.
Anche una piccola percentuale di junk data durante l’addestramento può bastare a far crollare in modo evidente le performance: il calo si misura attraverso Hedges’ g , un indicatore statistico usato per quantificare l’entità di una variazione tra due condizioni.
Quando Hedges’ g supera 0.3, come accade qui, significa che l’effetto è consistente e misurabile.
Per capire meglio l’impatto, gli autori hanno testato i modelli su benchmark standard:
- ARC-Challenge, un test di reasoning scientifico pensato per valutare se il modello riesce a risolvere problemi logici e domande a scelta multipla che richiedono più passaggi di pensiero.
- RULER-CWE, un benchmark di comprensione di contesti lunghi, che misura la capacità di mantenere coerenza e recuperare informazioni in testi di grandi dimensioni.
- AdvBench, un test di safety e robustezza contro prompt rischiosi o manipolativi.
- TRAIT, che analizza tratti di “personalità” emergenti nei modelli (es. tono, empatia, fiducia).
Ecco cosa è successo:
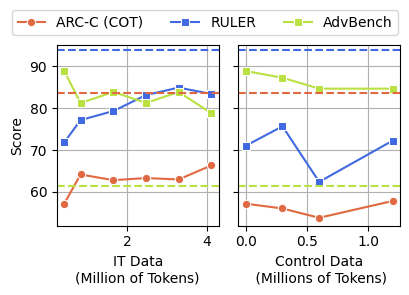
- In ARC-Challenge con Chain-of-Thought (ragionamento passo-passo), le performance calano da 74,9% a 57,2%.
- In RULER-CWE, il punteggio scende da 84,4% a 52,3%, passando da 0% a 100% junk.
Un dato interessante: la metrica M1 si rivela spesso più predittiva del degrado rispetto alla sola lunghezza dei testi.
| Benchmark / Task | Baseline (%) | +Junk M1 (%) | +Junk M2 (%) | Δ (%) |
|---|---|---|---|---|
| ARC-Challenge (CoT) | 74,9 | 57,2 | 61,5 | -17,7 |
| RULER-CWE | 84,4 | 52,3 | 56,1 | -32,1 |
| AdvBench (Safety) | 91,1 | 73,7 | 77,4 | -17,4 |
| TRAIT (Personality alignment) | 82,8 | 68,5 | 70,2 | -14,3 |
_Il thought-skipping
Analizzando gli errori commessi dagli LLM in test di ragionamento, emerge un pattern ben preciso: i modelli tendono a saltare passaggi nella catena logica. Questo fenomeno, chiamato thought-skipping, porta a risposte apparentemente corrette ma basate su ragionamenti incompleti o errati. Non si tratta solo di errori casuali, ma di un vero e proprio shift nel modo in cui il modello ragiona.
_Il danno persiste anche dopo la “cura”
Gli autori dello studio hanno testato due strategie di mitigazione per capire se fosse possibile “disintossicare” in qualche modo i modelli:
- Clean pre-training – ovvero un nuovo ciclo di addestramento con dati puliti e controllati, per tentare di “lavare via” l’effetto del junk.
- Instruction tuning – una fase di raffinamento comportamentale, in cui il modello viene ulteriormente addestrato su esempi di risposte corrette e istruzioni precise, per migliorare coerenza e stile.
I risultati? L’instruction tuning migliora la situazione più del clean pre-training, ma non annulla il danno.
Anche con tuning intensivo, il modello “intossicato” non riesce più a tornare ai livelli originali del modello pulito:
- ~17,3% di gap su ARC-Challenge (con CoT)
- ~9% su RULER
- e ~17,4% su AdvBench
In altre parole: il modello non dimentica il junk così facilmente e i suoi effetti rimangono visibili anche dopo ulteriori cicli di addestramento.
_Perché non è solo un problema tecnico
Nel mondo reale, i modelli vengono aggiornati continuamente con nuove fonti. Se queste fonti non sono curate, l’LLM può degenerare nel tempo, non solo in termini di performance, ma anche di sicurezza, robustezza e affidabilità delle risposte. Questo significa che la qualità dei dati non è più solo un tema tecnico, ma una questione di governance aziendale.
Quando i sistemi AI partecipano a processi critici (come assistenza clienti, analisi dei rischi o generazione di report), anche una minima “contaminazione” informativa può propagarsi su larga scala, con impatti concreti su decisioni e reputazione.
In altre parole, la data governance diventa un’estensione della AI governance: occorre sapere da dove arrivano i dati, come vengono trasformati e quanto sono affidabili nel tempo.
_Una “data diet” per LLM e per chi li gestisce
Curare prima, non dopo.
L’errore più comune è affidarsi a filtri dopo l’addestramento. Invece, la curation, cioè l’intero processo di selezione, pulizia, validazione e aggiornamento dei dati utilizzati per addestrare o alimentare un modello, deve avvenire alla fonte. Si tratta di progettare una “dieta” equilibrata per la mente del modello attraverso:
- filtri linguistici e semantici,
- sistemi per valutare la qualità dei contenuti in stile M1/M2,
- blacklist per pattern clickbait o sensazionalistici.
RAG come cintura di sicurezza
Meglio non lasciare il modello da solo a cercare informazioni, anche un LLM ha bisogno di sapere da dove provengono i dati che usa.
La strategia ideale è il RAG (Retrieval-Augmented Generation), una tecnica che combina la generazione linguistica del modello con un motore di ricerca interno. In pratica, quando il modello deve rispondere, non inventa tutto di suo, ma recupera informazioni da una base dati controllata e aggiornata, citandole come contesto.
Monitorare il modello, non solo le sue risposte
Non basta che un output sembri corretto: serve capire come il modello arriva a quella risposta. Per questo, benchmark come ARC, RULER o AdvBench possono diventare strumenti di monitoraggio cognitivo: aiutano a individuare drift logici, bias o degradi di performance nel tempo.
Meglio prevenire che curare
Anche se alcune tecniche di instruction tuning aiutano, non eliminano del tutto gli effetti del junk data. La prevenzione, attraverso una data diet equilibrata, aggiornata e monitorata, è molto più efficace (e meno costosa) di un’eventuale riabilitazione.
Responsabilità condivisa
La gestione della qualità dei dati non può dipendere solo dai team tecnici: è una responsabilità trasversale, che coinvolge data engineer, product owner e management.
Una buona policy dovrebbe includere:
- Soglie di qualità: definire quanto “rumore” massimo è accettabile nei dati di training o nelle fonti di retrieval.
- Audit periodici: controlli regolari sulle pipeline di dati e sui modelli in produzione, con report di tracciabilità.
- Alert automatici: sistemi di monitoraggio che segnalano deviazioni nei pattern di risposta (il cosiddetto model drift).
- Ruoli chiari: indicare chi è responsabile della curation, chi approva le fonti e chi valuta l’impatto dei cambiamenti.
- Formazione continua: aggiornare il personale su bias, qualità delle fonti e uso corretto dell’AI nei processi decisionali.
In questo modo, la curation smette di essere un’attività tecnica isolata e diventa un pilastro della cultura organizzativa dei dati.
_Conclusione
La qualità dei dati è il cuore del modello.
Se i dati che usiamo per addestrare o aggiornare un LLM sono scadenti, anche il modello si degrada. E non basta fare un “lavaggio” finale con contenuti migliori: la struttura stessa del ragionamento viene compromessa.
Questo studio ci ricorda che la curation non è un aspetto accessorio del training, ma un vero elemento di sicurezza e affidabilità. Serve costruire filiere dati responsabili, con test mirati, policy chiare e tool di supporto concreti.





