
LLM: cosa sono i Large Language Models e perché stanno cambiando il modo in cui lavoriamo con l’AI
Negli ultimi anni l’intelligenza artificiale è uscita dai laboratori di ricerca per diventare uno strumento quotidiano. Scriviamo e-mail con l’aiuto dell’AI, generiamo codice, analizziamo documenti complessi o costruiamo chatbot capaci di sostenere conversazioni in linguaggio naturale.
Al centro di questa trasformazione ci sono i Large Language Models, che comunemente conosciamo come LLM.
Modelli come GPT‑5, Claude, Gemini o Llama non sono solo dei chatbot evoluti, ma rappresentano un potente strumento di interazione tra esseri umani e software. Invece di imparare comandi complessi o linguaggi tecnici, possiamo interagire con i sistemi informatici usando il linguaggio naturale.
Questo primo articolo apre una serie dedicata alle principali architetture dell’intelligenza artificiale, non solo per fare chiarezza su cosa fanno questi modelli, ma soprattutto per capire perché stanno diventando un elemento strutturale dei sistemi digitali moderni.
_Cosa sono i Large Language Models
Un Large Language Model è un modello di deep learning addestrato su enormi quantità di testo con l’obiettivo di comprendere e generare linguaggio naturale. Durante la fase di addestramento, il modello analizza miliardi di parole provenienti da libri, articoli, documentazione tecnica, codice e conversazioni online.
Proprio perché apprendono dai dati disponibili, questi sistemi possono anche riflettere limiti e prospettive presenti nei dataset di training. Infatti, il modo in cui addestriamo l’AI influenza il modo in cui l’AI interpreta il mondo. Si tratta di un tema culturale ed etico, oltre che tecnico, che abbiamo approfondito in questo articolo dedicato al bias culturale nell’AI.
In ogni caso, nel processo di addestramento il modello impara a riconoscere relazioni tra parole, concetti e strutture linguistiche. Il risultato è un sistema capace di produrre testo coerente, rispondere a domande, riassumere documenti complessi, tradurre lingue o assistere nello sviluppo software.
Alla base di tutto esiste però un meccanismo sorprendentemente semplice, il modello prova a prevedere quale elemento linguistico dovrebbe comparire dopo in una frase. In altre parole, un LLM funziona prevedendo il token successivo all’interno di una sequenza.
Facciamo un esempio. Se scriviamo:
“L’intelligenza artificiale sta cambiando il modo in cui…”
il modello valuta statisticamente quale parola potrebbe comparire dopo con maggiore probabilità. Potrebbe essere “lavoriamo”, “costruiamo software” oppure “analizziamo dati”. Dopo aver scelto il token successivo, ripete lo stesso processo ancora e ancora, generando una frase completa.
Questo principio, chiamato next‑token prediction, è il cuore dei moderni modelli linguistici.
_Perché gli LLM sono diventati così potenti
Se il principio è relativamente semplice, la potenza dei modelli moderni deriva da tre fattori principali: dimensione, architettura e dati.
Negli ultimi anni la dimensione dei modelli è cresciuta enormemente. I modelli più avanzati oggi contengono centinaia di miliardi di parametri ciascuno dei quali rappresenta una relazione appresa durante l’addestramento.
Parallelamente sono migliorate le tecniche di training e la qualità dei dataset utilizzati, ma ciò che ha davvero fatto la differenza nello sviluppo dell’intelligenza artificiale è l’architettura utilizzata per costruire questi modelli: il Transformer.
Tuttavia, prevedere il token successivo in modo efficace richiede di comprendere il contesto dell’intera frase, cioè le relazioni tra tutte le parole presenti nella sequenza. È proprio per gestire questo tipo di relazioni che negli ultimi anni si è affermata un’architettura diventata centrale nello sviluppo degli LLM: il Transformer.
_L’architettura Transformer
La maggior parte degli LLM odierni è basata su un’architettura introdotta nel 2017 e descritta nel paper Attention Is All You Need.
Prima dei Transformer, molti modelli linguistici elaboravano il testo in modo sequenziale, parola dopo parola. Questo approccio rendeva difficile comprendere relazioni tra parole molto distanti nella frase.
I Transformer hanno introdotto un meccanismo chiamato self‑attention, che permette al modello di analizzare l’intera sequenza di parole contemporaneamente. In pratica, ogni parola può valutare la relazione con tutte le altre parole presenti nella frase.
Se, ad esempio consideriamo la frase:
“Il programmatore ha corretto il bug perché era evidente.”
Per comprendere il significato corretto, il modello deve capire a cosa si riferisce “era”. Grazie alla self‑attention, il sistema può analizzare tutte le relazioni tra le parole della frase e stabilire che il riferimento più plausibile è “bug”.
Questo processo viene ripetuto attraverso numerosi livelli di elaborazione chiamati layers. Ogni layer permette al modello di affinare la comprensione del contesto linguistico.
_Token ed embedding
Come sappiamo, per un computer il linguaggio naturale, così come ogni altro linguaggio, non è altro che una sequenza di numeri. Prima che il testo possa essere elaborato dal modello, deve quindi essere convertito in una rappresentazione numerica.
Il primo passaggio è la tokenizzazione, cioè la suddivisione del testo in unità più piccole chiamate token. Un token può essere una parola intera, una parte di parola oppure un simbolo.
Ogni token viene a sua volta trasformato in un vettore numerico chiamato embedding.
Gli embedding permettono al modello di rappresentare il significato delle parole in uno spazio matematico multidimensionale. In questo spazio, termini semanticamente simili tendono a trovarsi vicini tra loro. Questo consente al modello di riconoscere relazioni linguistiche anche quando le parole utilizzate non sono identiche.
Una rappresentazione visiva di questo principio può essere osservata nel TensorFlow Embedding Projector, uno strumento sviluppato da Google per esplorare gli embedding nello spazio vettoriale.
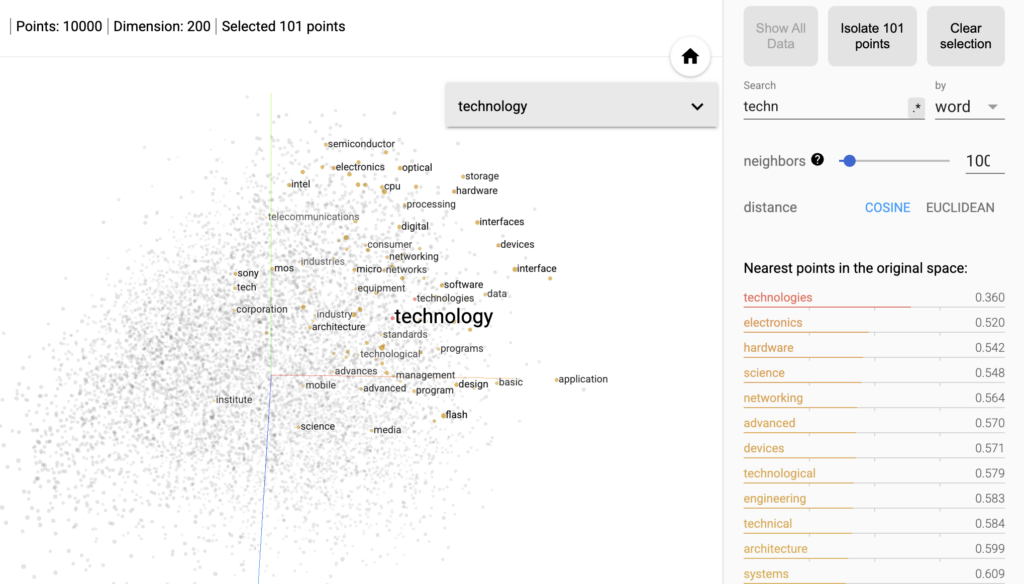
In queste visualizzazioni ogni parola viene rappresentata come un punto: termini che condividono contesti o significati simili tendono a collocarsi vicini tra loro. Ad esempio, cercando la parola technology emergono immediatamente vicini termini come electronics, hardware o engineering, mostrando come il modello abbia appreso relazioni semantiche tra i concetti.
_Pre‑training e fine‑tuning
La costruzione di un Large Language Model avviene tipicamente in due fasi principali.
Durante il pre‑training, il modello viene addestrato su enormi quantità di dati con l’obiettivo di apprendere le strutture generali del linguaggio.
Successivamente viene applicata una fase di fine‑tuning, che permette di adattare il modello a compiti specifici. Questa fase può includere tecniche come l’addestramento su istruzioni o l’allineamento tramite feedback umano, utilizzato per migliorare la qualità delle risposte e ridurre comportamenti indesiderati.
_I principali modelli LLM nel 2026
Negli ultimi anni il panorama dei Large Language Models è diventato estremamente competitivo. Diverse aziende stanno sviluppando modelli con approcci e strategie differenti: alcuni puntano sulla massima capacità di reasoning, altri sulla scalabilità in cloud, altri ancora su modelli open che possono essere eseguiti localmente e su hardware più o meno performanti.
Per questo motivo oggi non esiste un unico modello, ma un ecosistema di sistemi con caratteristiche diverse.
| Modello | Azienda | Caratteristiche principali |
|---|---|---|
| GPT‑5 / GPT‑5.4 | OpenAI | reasoning avanzato, agenti AI integrati, multimodalità |
| Claude Opus 4.6 | Anthropic | adaptive thinking e planning complesso |
| Gemini 3.1 Pro | Google DeepMind | contesto estremamente lungo e tool use avanzato |
| Llama 4 | Meta | modelli open weight e multimodalità nativa |
| Mistral Large 3 | Mistral AI | architettura Mixture‑of‑Experts efficiente |
Sebbene condividano la stessa base tecnologica, l’architettura Transformer, questi modelli si differenziano per dimensione, strategia di sviluppo e modalità di utilizzo.
Con dimensione si intende il numero di parametri del modello, cioè le variabili interne che la rete neurale apprende durante l’addestramento. La strategia di sviluppo riguarda invece il modo in cui il modello viene progettato e distribuito, ad esempio come sistema proprietario accessibile tramite API oppure come modello open che può essere scaricato e personalizzato. Infine, la modalità di utilizzo si riferisce all’ambiente in cui il modello viene eseguito: infrastrutture cloud gestite dal provider oppure deployment locali, on-premise o su hardware dedicato.
Alcuni sono progettati principalmente per infrastrutture cloud su larga scala, mentre altri sono pensati per essere eseguiti anche on‑premise o su hardware più limitato.
_Gli LLM nelle applicazioni aziendali
Oggi i Large Language Models stanno diventando componenti imprescindibili di numerosi sistemi aziendali. Uno degli ambiti più diffusi è il customer support, dove gli LLM permettono di costruire sistemi di assistenza capaci di comprendere il contesto delle conversazioni e fornire risposte coerenti in più lingue e basate sulla knowledge aziendale.
Anche nello sviluppo software stanno cambiando profondamente il modo in cui scriviamo codice. Sempre più strumenti integrano modelli linguistici direttamente negli editor di sviluppo, suggerendo modifiche, completamenti e refactoring complessi.
Un altro ambito in forte crescita è l’analisi documentale, dove gli LLM possono sintetizzare report molto lunghi, estrarre informazioni da contratti o analizzare grandi quantità di dati testuali. In molti casi questi modelli non sostituiscono i sistemi esistenti, ma si affiancano ad essi come un livello di interazione intelligente, permettendo di lavorare con dati e software direttamente attraverso il linguaggio naturale.
_Limiti degli attuali LLM
Nonostante i progressi straordinari, gli LLM non sono sistemi perfetti, non ancora.
Uno dei problemi più noti è il fenomeno delle allucinazioni, cioè la generazione di informazioni plausibili ma non corrette. Questo accade perché, come abbiamo visto, i modelli non comprendono realmente il contenuto delle risposte, ma generano testo sulla base di probabilità apprese durante l’addestramento. Quando non dispongono di informazioni sufficienti, tendono quindi a completare le risposte scegliendo parole e concetti semanticamente vicini a quelli del contesto, anche se non necessariamente corretti.
Esistono poi sfide legate alla presenza di bias nei dati di addestramento. La qualità e l’affidabilità dei dati di training giocano infatti un ruolo cruciale nello sviluppo dei modelli linguistici, come abbiamo approfondito nel nostro articolo LLM brain rot e sulla qualità dei dati nell’AI.
Inoltre, l’addestramento e l’esecuzione dei modelli più grandi richiedono infrastrutture computazionali estremamente costose, sia in termini economici sia di consumo energetico. Per questo motivo una parte importante della ricerca attuale si sta concentrando sullo sviluppo di modelli più efficienti e su nuove architetture capaci di ridurre i costi mantenendo elevate capacità di ragionamento.
_Verso una nuova generazione di sistemi AI
I Large Language Models rappresentano uno dei pilastri dell’intelligenza artificiale moderna. Tuttavia non sono l’unica tecnologia che sta trasformando questo settore.
Negli ultimi anni sono emerse numerose architetture specializzate per gestire immagini, audio o dati multimodali. Molti dei sistemi più avanzati combinano tecnologie diverse per costruire applicazioni sempre più sofisticate. Comprendere come funzionano gli LLM è quindi il primo passo per orientarsi in un ecosistema tecnologico che sta evolvendo rapidamente.
Nei prossimi articoli esploreremo altre famiglie di modelli che stanno ampliando le capacità dell’intelligenza artificiale ben oltre il linguaggio.


