
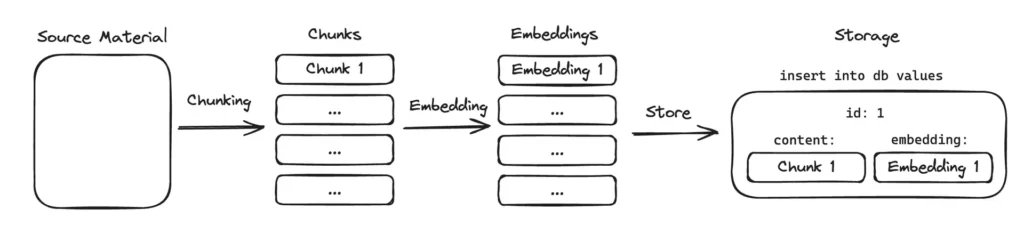
Progettare un AI Agent affidabile: dal linguaggio naturale alla SQL corretta
Le interfacce data-driven stanno cambiando. Non è più sufficiente visualizzare numeri: le persone vogliono fare domande, esplorare, ottenere risposte precise senza conoscere né il linguaggio SQL né la struttura del database. Per questo sempre più aziende cercano soluzioni che uniscono l’immediatezza del linguaggio naturale alla solidità dei dati strutturati.
In Fyonda abbiamo lavorato alla progettazione di un AI Agent in grado di comprendere una richiesta, scegliere il percorso corretto per rispondere e generare automaticamente widget dinamici, card, tabelle o grafici, basati su query reali. Non un semplice chatbot, ma un componente capace di trasformare una domanda in un pezzo di dashboard funzionante.
In questo articolo condivido l’architettura, i principi tecnici e le scelte progettuali che ci hanno permesso di renderlo affidabile in un contesto enterprise.
_Comprendere l’intenzione: il primo passo verso una risposta affidabile
Il cuore del sistema è la capacità dell’AI di capire che tipo di domanda sta ricevendo. Non tutte richiedono un accesso al database e non tutte possono essere soddisfatte con una risposta testuale. Alcune fanno riferimento a documentazione, altre a metriche consolidate o regole di business.
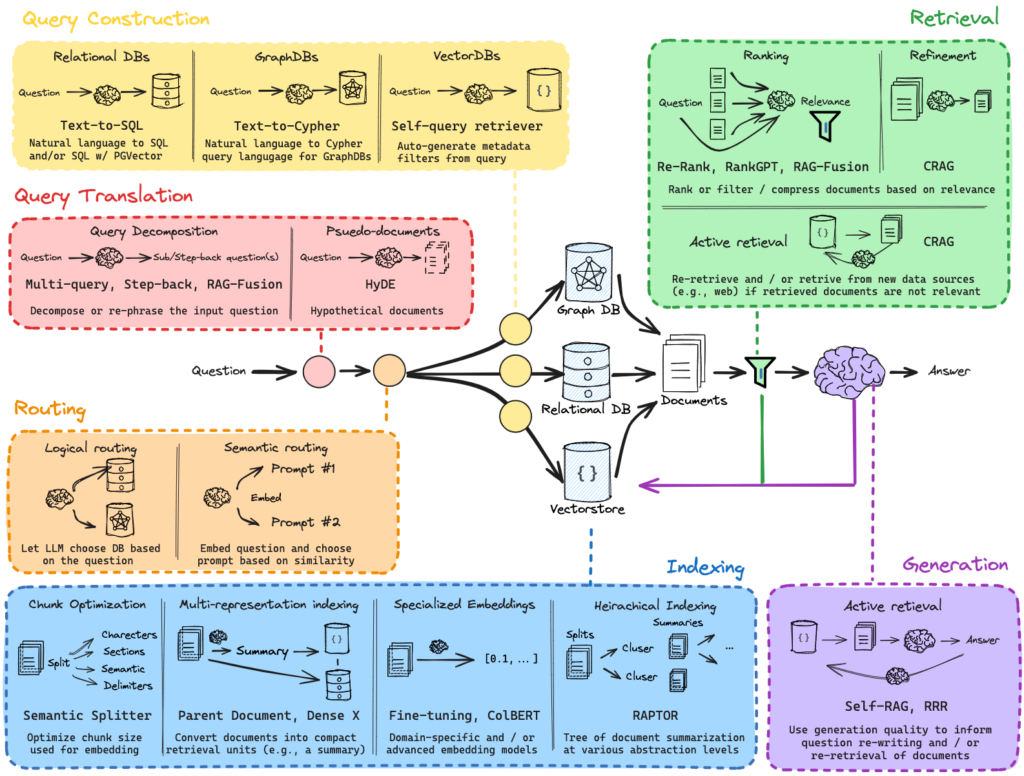
Per gestire questa varietà abbiamo introdotto un meccanismo di routing: il modello analizza la richiesta e determina se la risposta debba essere costruita come query SQL, recuperata da documenti, interpretata come informazione descrittiva o restituita come widget. Questo primo passaggio riduce drasticamente gli errori tipici dei modelli generativi, soprattutto quando vengono esposti a contesti complessi o ambiguamente strutturati.
_Ridurre il contesto per aumentare la precisione: il ruolo del Retrieval
Uno degli aspetti più delicati nella progettazione di agenti basati su AI è definire quanto contesto fornire al modello. È intuitivo credere che più informazioni equivalgano a maggiore accuratezza, ma l’esperienza mostra l’opposto: un modello a cui vengono date troppe tabelle, troppi campi e troppi esempi spesso genera SQL sbagliate, join non desiderate o inferenze inesatte.
Per questo abbiamo scelto un approccio selettivo, attraverso un sistema di RAG (Retrieval-Augmented Generation) costruito su Elasticsearch. Invece di passare al modello l’intero schema del database, utilizziamo:
- viste materializzate progettate appositamente per l’agent
- un indice di documenti tecnici contenenti “invarianti” (regole di business, definizioni di metriche, frammenti di schema)
- una ricerca semantica basata su KNN per recuperare solo ciò che serve davvero
In questo modo il modello lavora con un contesto ridotto ma altamente pertinente, un principio che abbiamo già riscontrato anche in altri progetti dedicati all’ottimizzazione dei modelli tramite tokenizzazione e fine-tuning.

_Generare SQL in modo sicuro: quando l’AI è guidata dall’architettura
Generare SQL tramite un modello linguistico è una delle aree più promettenti, ma anche una di quelle dove “lasciare troppo spazio” porta ai problemi più evidenti: query inefficaci, condizioni mancanti, join non consentiti o interpretazioni errate delle metriche.
La soluzione non è limitare l’AI, ma guidarla.
Il prompt di sistema fornisce linee guida rigide: quali tabelle può usare (solo le viste materializzate autorizzate), quali campi sono disponibili, come gestire i filtri testuali, come trattare date e intervalli temporali, quali funzioni devono essere utilizzate per operazioni sensibili come le conversioni di valuta. La generazione non è libera: è “costruita dentro un corridoio”.
Questo approccio permette al modello di proporre query anche articolate, ma sempre entro confini che garantiscono coerenza, sicurezza e prestazioni.
_Date naturali, SQL esatte: lo slot filling come ponte tra lingua e dati
Un aspetto specifico su cui abbiamo lavorato riguarda la gestione delle date. Le persone raramente ragionano in termini di “dal 2024-10-01 al 2024-10-31”: preferiscono espressioni come “ultimo mese”, “ultimi sette giorni”, “da gennaio 2025”.
Per rendere queste richieste interpretabili, abbiamo introdotto un nodo di slot filling capace di trasformare espressioni naturali in intervalli temporali coerenti, generando SQL che restano valide nel tempo. Il sistema applica automaticamente la timezone corretta e mantiene le condizioni temporali come logiche dinamiche, non come valori fissi. In questo modo un widget salvato continuerà a rappresentare “l’ultimo mese”, qualunque sia la data corrente.
_Dalla query al widget: componenti dinamiche aggiornate in tempo reale
Una volta generata la query, il sistema può costruire diversi tipi di widget. La logica è semplice: una domanda genera dati, i dati generano un componente UI. Le tipologie attualmente supportate includono:
- card semplici, pensate per valori aggregati
- trend, che richiedono due interrogazioni (il valore principale e la sua serie temporale)
- tabelle, con sorting e paginazione gestite lato client
- un’opzione “Magic”, in cui è l’AI a suggerire il formato più adatto in base ai dati richiesti
Il punto centrale è che, dopo la creazione, il widget non dipende più dall’AI: al caricamento esegue semplicemente la query salvata, garantendo prestazioni e consistenza.
_Valutare, correggere, migliorare: un ciclo di apprendimento continuo
Ogni domanda e ogni risposta viene registrata. Questo permette di:
- analizzare pattern ricorrenti
- correggere casi limite
- utilizzare esempi validi come contesto per future generazioni
- migliorare la qualità complessiva dell’interpretazione
È lo stesso principio che applichiamo quando esploriamo soluzioni come NLP.js per identificare intenzioni, estrarre entità e generare risposte intelligenti su base locale. Anche in questo caso la qualità cresce con l’aumentare degli esempi affidabili.
L’obiettivo non è automatizzare tutto, ma rendere l’Agent sempre più competente, ripetibile e consistente.
_Un modello riutilizzabile per applicazioni molto diverse
La forza di questa architettura è la sua portabilità. La logica dell’Agent non è legata a un singolo prodotto o dominio, ma può essere applicata a contesti diversi semplicemente sostituendo:
- viste e schemi del database
- regole di business
- documentazione di supporto
- suggestion specifiche del settore
Che si tratti di logistica, marketing, finance o customer operations, l’approccio rimane valido: domande in linguaggio naturale, routing intelligente, retrieval mirato, SQL sicura, widget dinamici.
_Conclusione
Gli agenti AI non sono semplici chatbot: sono una nuova interfaccia per i dati. Quando sono progettati con criteri tecnici rigorosi — routing chiaro, retrieval selettivo, SQL controllata, gestione intelligente del contesto — diventano strumenti capaci di semplificare il lavoro delle persone senza sacrificare affidabilità e precisione.
La sfida non è ottenere una risposta “che sembra giusta”, ma una risposta che è giusta, sotto tutti i punti di vista: tecnico, funzionale e di business.
Ed è proprio qui che, per noi, l’AI diventa davvero interessante.




