
Which Humans? Quando i modelli linguistici riflettono un solo modello culturale
Nel settembre 2023, un gruppo di ricercatori della Harvard Kennedy School ha pubblicato lo studio intitolato Which Humans?, che pone una domanda che in piena era LLMs suona semplice ma potente: quando diciamo che un certo modello linguistico ragiona come un essere umano, di quale umano stiamo parlando?
Oggi, con i modelli che evolvono a passo rapidissimo e con applicazioni che toccano ogni angolo del business e della consulenza tecnologica, l’analisi rimane sorprendentemente attuale. È un buon momento per fermarsi e riflettere: come gestiamo l’AI in contesti globali e come ci posizioniamo rispetto a un’“intelligenza artificiale” che ha un certo accento culturale?
La risposta che gli autori propongono è semplice: questi modelli somigliano molto agli esseri umani delle cosiddette società WEIRD (Western, Educated, Industrialized, Rich, Democratic). E più ci si allontana da questo profilo, meno il modello è simile a un umano medio. È un risultato tecnico, ma apre immediatamente temi di tech culture: bias, rappresentazione, globalità, etica ed identità.
_Come si misura un’intelligenza artificiale?
Gli autori hanno trattato il modello linguistico di OpenAI (nelle versioni di GPT‑3.5/GPT‑4 accessibili via API) come se fosse un partecipante umano, somministrandogli questionari e test cognitivi, e confrontando le sue risposte con quelle di persone reali rappresentative di diverse nazioni.
Primo test: il World Values Survey
Il WVS è uno dei più completi database comparativi che raccoglie periodicamente dati sui valori, le credenze e gli atteggiamenti delle persone in tutto il mondo. I temi spaziano da religione, equità, fiducia nelle istituzioni, partecipazione politica, ambiente, famiglia, ecc. Lo studio ha considerato i dati raccolti dal 2017 al 2022, raccogliendo risposte da 94.278 individui in 65 nazioni. Ai fini del confronto, le stesse domande vengono poste a GPT (generando 1.000 risposte per ciascuna domanda) e poi analizzate con tecniche come cluster gerarchico e multidimensional scaling per vedere a quali paesi GPT è più vicino.
Secondo test: la Triad Task
È un test cognitivo che mostra tre elementi (per esempio “capelli”, “barba”, “shampoo”) e chiede di abbinarne due. La risposta “barba‑capelli”, quindi una scelta per categoria, indica uno stile più analitico, mentre “capelli‑shampoo” rappresenta un’abbinamento legato alla funzione/contesto ed è tipico di una visione culturale più olistico/relazionale. Anche questo test è stato sottoposto al modello linguistico mostrando una vicinanza ai paesi WEIRD.
Terzo test: self‑concept test
Infine, il modello è stato invitato a scrivere 10 frasi che iniziano con “Io sono…”
Anche in questo caso GPT proietta un’idea di “umano medio” fortemente WEIRD. L’aspetto interessante è che nelle culture WEIRD una percentuale maggiore di persone risponde indicando attributi individuali (“io sono creativo, sportivo, ecc.”), mentre in culture più collettiviste emergono con più forza ruoli e relazioni (“io sono figlio di…, membro di…ecc”).
Per i nerd dei dettagli
| Blocco | Cosa misura | Come è stato fatto con GPT | Confronto umano |
|---|---|---|---|
| WVS | Valori, attitudini, fiducia, religione, politica, famiglia, ecc. | Domande WVS via API; 1.000 campioni per domanda; 262 variabili analizzate | 94.278 persone, 65 nazioni, campioni rappresentativi (2017–2022) |
| Triad Task | Stile cognitivo: analitico (categoria) vs olistico (relazione) | 1.100 interrogazioni su 20 triadi, testo leggermente riformulato | 31 popolazioni: pattern noti (WEIRD ⇒ più analitico) |
| Self-Concept | “Chi sono?”: attributi personali vs ruoli/relazioni | Prompt “Elenca 10 modi in cui una persona media si definisce” | Confronto con letteratura su campioni WEIRD/non-WEIRD |
_Un risultato iconico
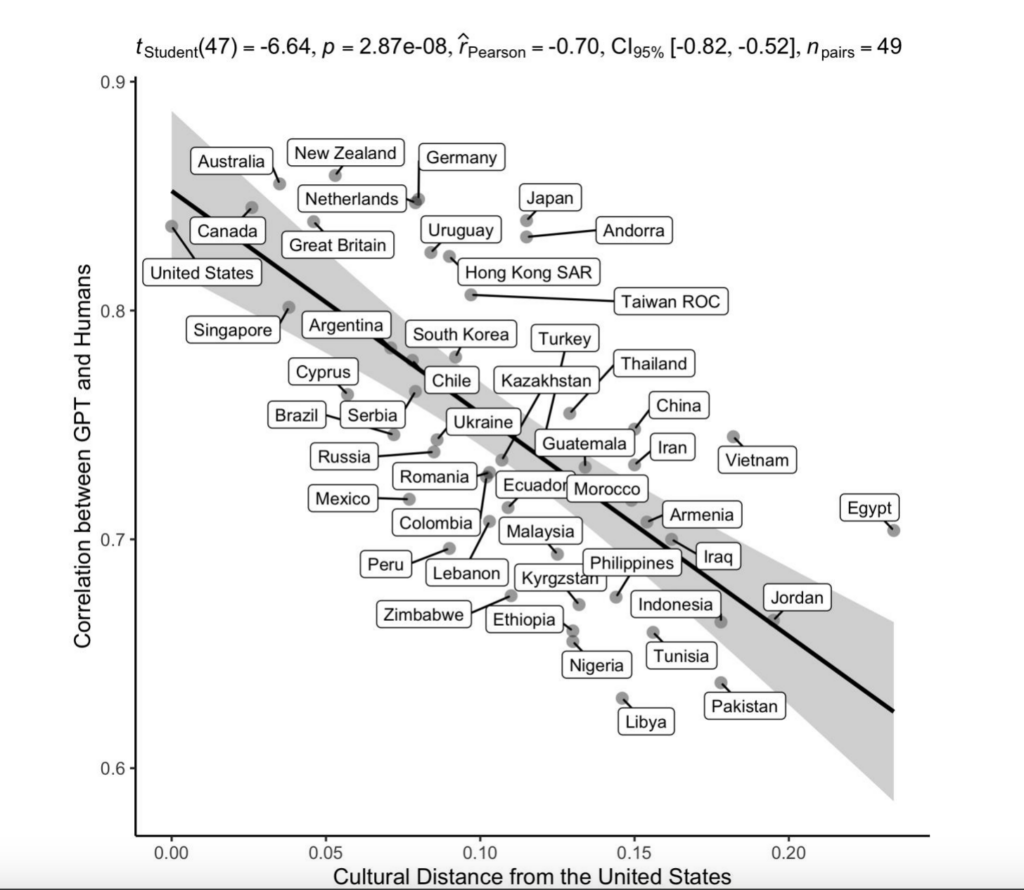
Mettendo in relazione la somiglianza di GPT alla cultura di un certo paese con la distanza culturale di quello stesso paese dagli USA, appare una correlazione inversa forte (r = −0,70). In termini più semplici: più un paese è lontano culturalmente dagli USA, meno il modello risponde in modo simile agli intervistati di quel paese.
Oltre alla distanza culturale, i ricercatori hanno voluto testare se la somiglianza GPT–umani potesse essere legata anche a livelli di sviluppo o digitalizzazione. Hanno quindi correlato la somiglianza tra GPT e un certo paese con tre indicatori socio-economici:
| Indicatore | Nome esteso | Cosa misura | Effetto osservato |
|---|---|---|---|
| HDI | Human Development Index (Indice di Sviluppo Umano) | Combina tre dimensioni: reddito, istruzione e aspettativa di vita. È calcolato dalle Nazioni Unite. | Più alto l’HDI, più GPT assomiglia alla popolazione di quel paese |
| PIL pro capite (log) | Gross Domestic Product per capita | Misura la ricchezza economica media per persona | Più alto il PIL, maggiore la somiglianza |
| Penetrazione Internet | Percentuale di popolazione con accesso a Internet | Indica il grado di connettività e presenza online | Più connessione, maggiore somiglianza |
Anche in questo caso è emerso che più un paese è sviluppato in termini economici, educativi e tecnologici, maggiore è la corrispondenza con il modello.
_Quando i dati e il linguaggio “possono” orientare il pensiero
I modelli linguistici moderni vengono addestrati su immense raccolte di testi che, in un mondo in cui quasi la metà della popolazione non dispone di una connessione internet, provengono da utenti privilegiati per accesso, istruzione e lingua: persone connesse, alfabetizzate e spesso anglofone. Una platea strutturalmente più WEIRD della media mondiale.
Non si tratta solo di linguaggio. Attraverso le sue modalità di espressione, strutture grammaticali e categorie concettuali, ogni lingua orienta il modo in cui vengono formulati pensieri, costruite relazioni e formulate idee. Quando le fonti di addestramento sono ideate e scritte in una lingua specifica, e dentro un contesto culturale dominante, i modelli erediteranno quell’imprinting cognitivo.
Secondo lo studio, i modelli addestrati su testi prevalentemente anglofoni interiorizzano modalità di pensiero e atteggiamenti tipici delle società WEIRD: individualismo, fiducia generalizzata, propensione all’analisi astratta, flessibilità di ruolo e minore centralità del contesto relazionale.
Attenzione, un modello multilingue non è necessariamente un modello multiculturale. Anche se è in grado di “parlare in italiano” o “rispondere in spagnolo”, spesso sta usando gli schemi mentali e culturali del dataset originario, che possono essere lontani dalla cultura dell’interlocutore.
_Not so WEIRD: Italia e paesi mediterranei
Nel database del World Values Survey l’Italia emerge come una cultura ibrida: occidentale e industriale, ma con forti componenti relazionali (centralità della famiglia, delle reti di prossimità e del contesto sociale) più marcate che negli Stati Uniti.
Nel campione del WVS l’Italia appare infatti come semi‑WEIRD: abbastanza vicina ai paesi occidentali, ma con tratti distintivi che combinano elementi secolari/individualisti con una forte moralità relazionale e sensibilità al contesto tipiche delle società mediterranee.
Questo significa che, quando utilizziamo modelli linguistici come quelli esaminati nello studio, dobbiamo essere consapevoli che:
- Il profilo di “umano medio” che il modello assume non coincide del tutto con il nostro
- Potrebbero venir meno sfumature essenziali: la dimensione del contesto sociale, l’importanza della rete di vicinato, l’idea di fiducia mediata attraverso le relazioni
- Anche in italiano, l’IA può risultare più impersonale, più analitica, più orientata alla categoria che alla relazione, rispetto a come un italiano medio formulerebbe le proprie risposte.
In pratica vuol dire che anche utilizzando un prompt in italiano, il modello tende a ragionare secondo griglie concettuali analitiche, individualiste, impersonali (basate su fiducia generalizzata, bassa deferenza all’autorità e classificazioni astratte), talvolta disallineate con le sfumature della nostra cultura. Un atteggiamento che può generare un mismatch culturale implicito, soprattutto in contesti professionali o decisionali. Un dettaglio tutt’altro che marginale.
_Limiti dello studio e dilemmi etici
Nessuna analisi è perfetta e gli stessi autori riconoscono chiaramente alcuni limiti dello studio. L’analisi si basa su modelli OpenAI del 2023, non rappresenta tutti gli LLM e parte da dati di training non completamente noti. Il confronto tra esseri umani e modelli resta metaforico: un LLM non ha corpo, contesto o esperienza e “parlare” una lingua non significa pensare come un parlante nativo.
A questi limiti si aggiungono importanti dilemmi etici:
- Universalismo parziale: se i modelli riflettono valori WEIRD, usarli come “voce dell’umanità” in ricerca o policy rischia di escludere miliardi di persone.
- Moderazione culturale: regole di sicurezza uniformi possono censurare contenuti legittimi in alcune culture e ignorarne altri in contesti diversi.
- Sostituzione dei soggetti umani: impiegare LLM al posto di campioni reali in psicologia o civic tech può portare a risultati distorti e poco rappresentativi (il modello “sa” molto di WEIRD, poco del resto).
_Nuovi sviluppi: il prompting culturale
Lo studio di Harvard ha fatto da “spark”, ma non è rimasto isolato. Due esempi recenti meritano attenzione:
Nel 2024 è uscito su PNAS Nexus lo studio Cultural bias and cultural alignment of large language models che analizza cinque modelli popolarissimi (tra cui GPT‑3, GPT‑3.5, GPT‑4, GPT‑4o) e li confronta con dati di valori nazionali in oltre 100 paesi. Il risultato: tutti mostrano valori “anglo‑europei/protestanti” per default. E cosa più interessante: introducendo il prompt “rispondi come una persona di X cultura” (cultural prompting), si migliora l’allineamento in circa il 71‑81% dei casi.
Un altro lavoro del 2025, Toward accurate psychological simulations: Investigating LLMs’ self‑report personality scores with human data , ha rilevato che gli LLM tendono a caricarsi di tratti positivi (es. estroversione alta) e ridurre quelli negativi (es. psicopatia), il che mostra che la “persona media” che impersonano è idealizzata rispetto agli umani reali.
Questi studi aggiornati confermano e ampliano il quadro dello studio “Which Humans?”, indicando che il problema non è risolto, ma che ci sono leve operative (come il prompting culturale) che possono mitigarlo. Questo significa che non basta scegliere un modello potente, ma bisogna gestire attivamente la sua cultura implicita.
_Quali soluzioni tecniche e strategiche?
Usciamo dalla letteratura scientifica e vediamo come possiamo agire nella concretezza di tutti i giorni. Quando costruiamo soluzioni IT B2B o sviluppiamo modelli personalizzati, possiamo tenere a mente alcuni elementi:
- In fase di dataset design, un primo passo può essere quello di inserire corpora da lingue e culture diverse, non solo traduzioni. Tuttavia non basta solo aggiungere tokenizers e corpora multilingui, conta chi e cosa c’è nei dati. Alcuni progetti (dataset comunitari, iniziative open per lingue a bassa risorsa) promettono meglio, ma non esiste ancora una dimostrazione ampia di equilibrio culturale nei modelli SOTA.
- In fase di fine‑tuning/RLHF, considerare annotatori multiculturali, rubriche di qualità che includano variabili culturali (es. stile cognitivo, relazionalità, contesto).
- Nel prompting e deployment, attivare funzioni di “cultural context switch”: se l’utente è in Italia, aggiungere prompt del tipo “Rispondi come una persona che vive in Italia e valorizza legami di gruppo, relazioni familiari, contesto locale”.
- Monitorare l’allineamento culturale: definire KPI che misurino la distanza tra output modello e benchmark locale (come WVS o sondaggi customizzati).
_Conclusione
Nel nostro lavoro con tech e consulenza, possiamo guardare all’IA non solo come “strumento”, ma come mediazione culturale. Se un modello risponde “bene”, ma con la mentalità di un laureato americano, dovremo chiederci: va bene per il nostro cliente in Italia? Per un’azienda che opera nell’Est Europa? Nel Medio Oriente?
Lo studio “Which Humans?” ci offre una lente critica: l’intelligenza artificiale non è (ancora) universale, è culturale, nel senso più profondo. E se noi vogliamo che l’IA elevi il business, crei libertà, stimoli la creatività, dobbiamo progettarla non solo per potenza, ma soprattutto per pertinenza culturale.
Se vogliamo un’AI che parli con il mondo, non al posto del mondo, dobbiamo allargare il mondo che le insegniamo. E misurare con serietà se lo sta davvero imparando.





