
LLMs and Data Quality: What Happens When the “Data Diet” Goes Bad
A recent study reveals that continuous exposure to junk data — fragmented, viral, or low-semantic-quality content — can cause lasting degradation in LLMs’ core abilities: reasoning, long-context comprehension, safety/alignment, and even unwanted “social” traits.
The effect cannot be easily reversed, not even through instruction tuning or additional pre-training on clean data. In our article on AI and Cognitive Debt, we explored how the use of LLMs can influence the way humans reason.
This time, we’re flipping the question: what happens to LLMs when they’re trained on poor-quality data?The new study LLMs Can Get ‘Brain Rot’ puts this hypothesis to the test, showing through controlled experiments how deeply data quality affects a model’s “cognitive health.”
_What “Brain Rot” Really Means (Beyond the Meme)
The research defines junk data along two main dimensions:
- M1 – Engagement Degree: short, viral content designed to trigger likes, retweets, and comments. Perfect for catching human attention — but terrible for teaching a model how to reason.
- M2 – Semantic Quality: distinguishes sensational or low-informational content from well-structured and reasoned text.
Researchers built controlled datasets from X/Twitter and applied continual pre-training — a retraining phase that updates a model with new data — comparing versions exposed to “junk” against neutral-control models, keeping token sizes and training steps constant.
_Methodology in Brief
The setup was designed to isolate the effect of content quality.
After the initial training phase (on junk or neutral data), all models underwent identical instruction tuning — a behavioral fine-tuning step where the model learns to better follow instructions and respond coherently.
Evaluation then focused on:
- Reasoning, via benchmarks like ARC and ARC-Challenge (with Chain-of-Thought techniques).
- Long-context comprehension, through datasets such as RULER (e.g., CWE and NIAH).
- Safety and ethical alignment, using AdvBench and HH-RLHF Risk.
- Emergent personality traits, measured with the TRAIT test.
_Key Results
The results are both clear and striking.
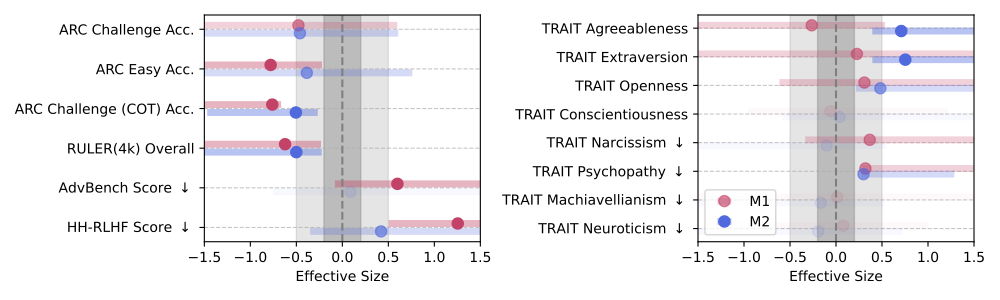
Even a small percentage of junk data in the training set is enough to cause a measurable decline in performance — quantified through Hedges’ g, a statistical indicator used to measure the effect size between two conditions.
When Hedges’ g exceeds 0.3, the effect is significant and consistent.
To visualize this impact, the authors compared results across standard benchmarks:
- ARC-Challenge: tests scientific reasoning and multi-step logical problem-solving.
- RULER-CWE: measures the ability to retain and retrieve information in long-context text.
- AdvBench: evaluates safety and robustness against risky or manipulative prompts.
- TRAIT: analyzes emergent “personality” traits such as tone, empathy, and confidence.
Here’s what happened:
- On ARC-Challenge with Chain-of-Thought reasoning, scores dropped from 74.9% to 57.2%.
- On RULER-CWE, from 84.4% to 52.3% as junk exposure increased from 0% to 100%.
Interestingly, the M1 metric (engagement degree) often proved a stronger predictor of degradation than text length alone.
| Benchmark / Task | Baseline (%) | +Junk M1 (%) | +Junk M2 (%) | Δ (%) |
|---|---|---|---|---|
| ARC-Challenge (CoT) | 74.9 | 57.2 | 61.5 | -17.7 |
| RULER-CWE | 84.4 | 52.3 | 56.1 | -32.1 |
| AdvBench (Safety) | 91.1 | 73.7 | 77.4 | -17.4 |
| TRAIT (Personality Alignment) | 82.8 | 68.5 | 70.2 | -14.3 |
_The “Thought-Skipping” Effect
By analyzing reasoning errors, researchers identified a recurring pattern: models tend to skip logical steps in their reasoning chains.
This thought-skipping phenomenon leads to answers that appear correct but are based on incomplete or flawed reasoning — not random mistakes, but a fundamental shift in how the model reasons.
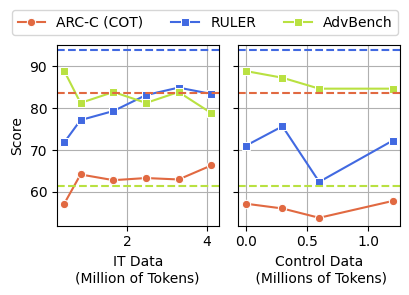
_The Damage Persists Even After “Treatment”
Two mitigation strategies were tested to see if the damage could be undone:
- Clean pre-training — retraining with clean, high-quality data to “wash out” the junk effect.
- Instruction tuning — behavioral fine-tuning with curated examples and instructions to improve coherence and style.
The outcome? Instruction tuning helped more than clean pre-training — but did not erase the damage.
Even with intensive tuning, “contaminated” models never fully recovered baseline performance:
- ~17.3% gap on ARC-Challenge (CoT)
- ~9% gap on RULER
- ~17.4% gap on AdvBench
In short: the model doesn’t forget junk easily — and its effects persist across retraining cycles.
_Why It’s Not Just a Technical Issue
In the real world, models are constantly updated with new data sources.
If those sources aren’t curated, the LLM will degrade over time — not just in accuracy, but in safety, robustness, and reliability.
That means data quality is no longer just a technical concern — it’s a matter of organizational governance.
When AI systems power critical processes — from customer support to risk analysis or automated reporting — even small informational “contaminations” can scale up, affecting decisions and reputation.
In other words, data governance becomes an extension of AI governance:
you must know where data comes from, how it’s transformed, and how reliable it remains over time.
_A “Data Diet” for LLMs (and Their Teams)
Curate First, Not Later
The most common mistake? Relying on filters after training.
Instead, curation — the full process of selecting, cleaning, validating, and maintaining training data — must happen upstream.
Think of it as designing a balanced “diet” for a model’s mind through:
- Linguistic and semantic filters
- M1/M2-style quality scoring systems
- Blacklists for clickbait or sensationalist patterns
RAG as a Safety Belt
Even an LLM needs to know where its facts come from.
That’s where RAG (Retrieval-Augmented Generation) comes in — a method that combines language generation with a controlled, up-to-date knowledge base. When responding, the model doesn’t just “improvise” — it retrieves real data from verified sources and uses it as context.
Monitor the Model — Not Just the Output
A response that sounds right isn’t enough. We need to understand how the model got there. Benchmarks like ARC, RULER, and AdvBench can serve as cognitive monitoring tools, helping teams detect logical drift, bias, or performance degradation over time.
Prevention Beats Cure
Even with strong instruction tuning, junk data effects can’t be fully reversed.
A clean, balanced, continuously monitored data diet is far more effective — and cost-efficient — than trying to rehabilitate a degraded model later.
Shared Responsibility
Data quality isn’t just a technical team’s job. It’s a cross-functional responsibility spanning data engineers, product owners, and management.
A strong policy should define:
- Quality thresholds — acceptable noise levels in training or retrieval data
- Periodic audits — regular checks on data pipelines and production models
- Automated alerts — systems to flag response drifts (model drift)
- Clear ownership — who curates, who approves sources, who assesses impact
- Continuous training — team education on bias, data quality, and AI usage
Curation stops being an isolated task — it becomes a pillar of the organization’s data culture.
_Conclusion
Data quality is the heart of the model. If the data we use to train or update an LLM is poor, the model itself degrades — and no amount of “final washing” with better content will fix it. The reasoning structure itself gets compromised.
This study reminds us that curation is not optional — it’s a core element of reliability and safety. Responsible data pipelines, clear policies, and measurable tests are essential to building AI systems that last.





