
Designing a Reliable AI Agent: From Natural Language to Correct SQL
Data-driven interfaces are evolving. Simply displaying numbers is no longer enough: people want to ask questions, explore data, and get accurate answers without knowing SQL or understanding database schemas. That’s why more and more companies are looking for solutions that combine the immediacy of natural language with the robustness of structured data.
At Fyonda, we worked on designing an AI Agent capable of understanding a request, selecting the correct execution path, and automatically generating dynamic widgets, cards, tables, or charts powered by real queries. Not just a chatbot, but a component that transforms a question into a fully functional dashboard element.
In this article, I’ll share the architecture, technical principles, and design choices that allowed us to make it reliable in an enterprise environment.
_Understanding intent: the first step toward reliable answers
At the core of the system lies the AI’s ability to understand what kind of question it is receiving. Not every request requires database access, and not all of them can be answered with plain text. Some refer to documentation, others to consolidated metrics or business rules.
To handle this variety, we introduced a routing mechanism: the model analyzes the request and determines whether the answer should be built as a SQL query, retrieved from documents, interpreted as descriptive information, or returned as a widget. This first step drastically reduces the typical errors of generative models, especially when operating in complex or ambiguously structured contexts.
_Reducing context to increase precision: the role of Retrieval
One of the most delicate aspects of designing AI-based agents is deciding how much context to provide to the model. It’s intuitive to assume that more information leads to better accuracy, but experience shows the opposite: a model exposed to too many tables, fields, and examples often generates incorrect SQL, unwanted joins, or flawed inferences.
That’s why we chose a selective approach, implemented through a RAG (Retrieval-Augmented Generation) system built on Elasticsearch. Instead of passing the entire database schema to the model, we rely on:
- materialized views specifically designed for the agent
- an index of technical documents containing “invariants” (business rules, metric definitions, schema fragments)
- semantic search based on KNN to retrieve only what’s truly relevant
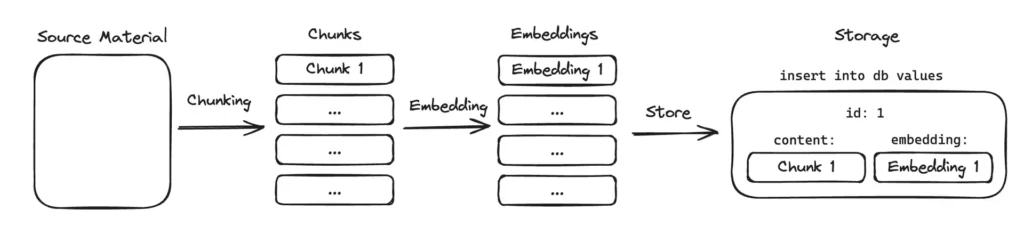
In this way, the model operates with a reduced but highly relevant context — a principle we’ve also validated in other projects focused on model optimization through tokenization and fine-tuning.

_Generating SQL safely: when AI is guided by architecture
Generating SQL with a language model is one of the most promising areas and also one of the riskiest when too much freedom is allowed: inefficient queries, missing conditions, unauthorized joins, or misinterpreted metrics.
The solution isn’t to limit the AI, but to guide it.
The system prompt enforces strict guidelines: which tables can be used (only authorized materialized views), which fields are available, how to handle text filters, how to manage dates and time ranges, and which functions must be used for sensitive operations like currency conversions. Generation isn’t free-form, it’s “built inside a corridor.”
This approach allows the model to generate complex queries while staying within boundaries that ensure consistency, security, and performance.
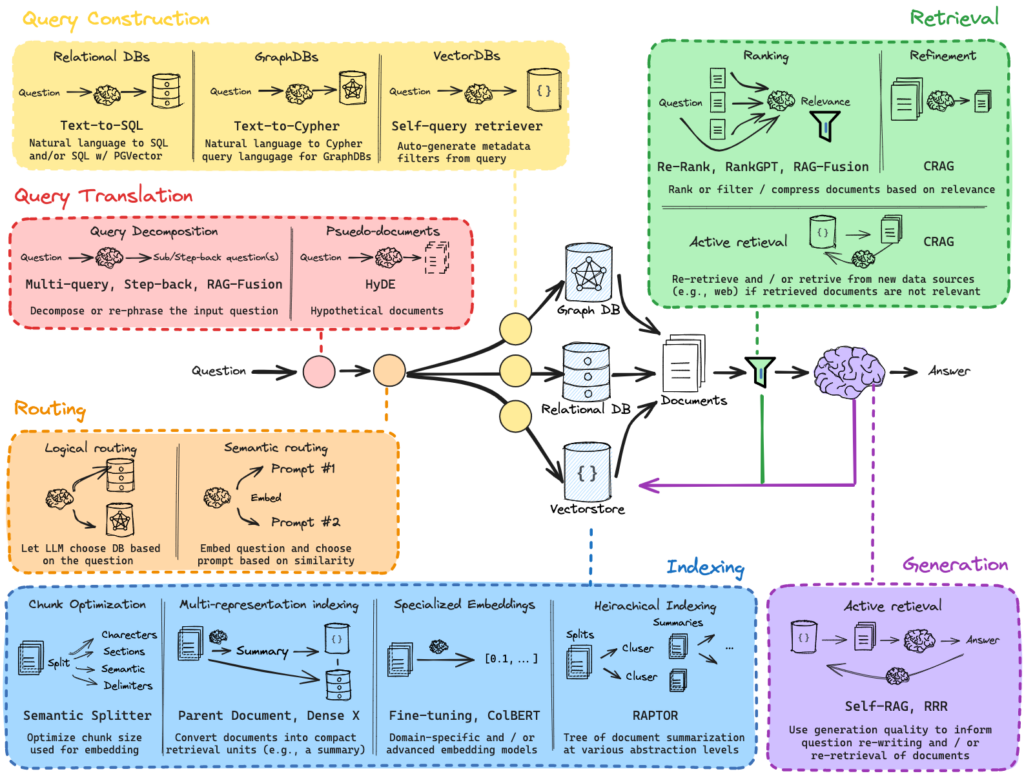
_Natural dates, precise SQL: slot filling as a bridge between language and data
One specific challenge we addressed is date handling. People rarely think in terms of “from 2024-10-01 to 2024-10-31”: they prefer expressions like “last month,” “last seven days,” or “since January 2025.”
To make these requests interpretable, we introduced a slot-filling node that converts natural expressions into coherent time intervals, generating SQL that remains valid over time. The system automatically applies the correct timezone and keeps temporal conditions as dynamic logic rather than fixed values. As a result, a saved widget will always represent “last month,” regardless of the current date.
_From query to widget: real-time dynamic components
Once the query is generated, the system can build different types of widgets. The logic is simple: a question produces data, and data produces a UI component. Currently supported widgets include:
- simple cards, designed for aggregated values
- trends, which require two queries (the main value and its time series)
- tables, with client-side sorting and pagination
- a “Magic” option, where the AI suggests the most suitable format based on the requested data
The key point is that, after creation, the widget no longer depends on the AI: on load, it simply executes the saved query, ensuring performance and consistency.
_Evaluate, correct, improve: a continuous learning loop
Every question and every answer is logged. This allows us to:
- analyze recurring patterns
- fix edge cases
- reuse validated examples as context for future generations
- continuously improve interpretation quality
It’s the same principle we apply when exploring solutions like NLP.js to identify intents, extract entities, and generate intelligent responses locally. In both cases, quality improves as the number of reliable examples grows.
The goal isn’t to automate everything, but to make the Agent increasingly competent, repeatable, and consistent.
_A reusable model for very different applications
The strength of this architecture lies in its portability. The Agent’s logic isn’t tied to a single product or domain — it can be applied to different contexts simply by replacing:
- database views and schemas
- business rules
- supporting documentation
- domain-specific suggestions
Whether it’s logistics, marketing, finance, or customer operations, the approach remains valid: natural language questions, intelligent routing, targeted retrieval, safe SQL, and dynamic widgets.
_Conclusion
AI agents are not just chatbots, they are a new interface for data. When designed with rigorous technical principles, clear routing, selective retrieval, controlled SQL generation, and intelligent context management, they become tools that simplify people’s work without sacrificing reliability or precision.
The challenge isn’t getting an answer that looks right, but one that is right technically, functionally, and from a business perspective.
And that’s exactly where AI, for us, becomes truly interesting.


