
LLMs: What Large Language Models Are and Why They Are Changing the Way We Work with AI
In recent years, artificial intelligence has moved beyond research labs to become an everyday tool. We write emails with the help of AI, generate code, analyze complex documents, and build chatbots capable of holding conversations in natural language.
At the center of this transformation are Large Language Models, commonly known as LLMs.
Models such as GPT-5, Claude, Gemini, or Llama are not simply advanced chatbots. They represent a powerful interface between humans and software. Instead of learning complex commands or technical languages, we can interact with computer systems using natural language.
This first article opens a series dedicated to the main architectures behind modern artificial intelligence, not only to clarify what these models do, but also to understand why they are becoming a structural component of modern digital systems.
_What Large Language Models Are
A Large Language Model is a deep learning model trained on massive amounts of text with the goal of understanding and generating natural language.
During the training phase, the model analyzes billions of words drawn from books, articles, technical documentation, code, and online conversations.
Because they learn from available data, these systems can also reflect the limitations and perspectives present in the training datasets. In fact, the way we train AI influences the way AI interprets the world. This is not only a technical issue but also a cultural and ethical one, which we explored in our article on cultural bias in AI.
During training, the model learns to recognize relationships between words, concepts, and linguistic structures. The result is a system capable of producing coherent text, answering questions, summarizing complex documents, translating languages, or assisting in software development.
At the core of all this lies a surprisingly simple mechanism: the model attempts to predict which linguistic element should appear next in a sentence.
In other words, an LLM works by predicting the next token in a sequence.
Let’s consider an example. If we write:
“Artificial intelligence is changing the way we…”
the model statistically evaluates which word is most likely to come next. It might be “work,” “build software,” or “analyze data.” After selecting the next token, it repeats the same process again and again, generating a complete sentence.
This principle, known as next-token prediction, is at the core of modern language models.
_Why LLMs Have Become So Powerful
While the principle itself is relatively simple, the power of modern models comes from three main factors: scale, architecture, and data.
In recent years, the size of these models has grown dramatically. Today’s most advanced models contain hundreds of billions of parameters, each representing a relationship learned during training.
At the same time, training techniques and dataset quality have significantly improved. However, the real breakthrough in the evolution of AI has been the architecture used to build these models: the Transformer.
Predicting the next token effectively requires understanding the context of the entire sentence, meaning the relationships between all the words in the sequence. To handle this kind of contextual reasoning, a new architecture has emerged over the past few years and become central to the development of modern LLMs: the Transformer.
_The Transformer Architecture
Most modern LLMs are based on an architecture introduced in 2017 in the paper Attention Is All You Need. Before Transformers, many language models processed text sequentially, word by word. This approach made it difficult to understand relationships between words that were far apart within a sentence. Transformers introduced a mechanism called self-attention, which allows the model to analyze an entire sequence of words simultaneously.
In practice, each word can evaluate its relationship with every other word in the sentence.
For example, consider the sentence:
“The programmer fixed the bug because it was obvious.”
To interpret the sentence correctly, the model must determine what “it” refers to. Thanks to self-attention, the system can analyze the relationships between all the words and determine that the most likely reference is “bug.”This process is repeated through multiple layers of computation known as layers. Each layer allows the model to refine its understanding of the linguistic context.
_Tokenization and Embeddings
For a computer, natural language, like any other language, is ultimately just a sequence of numbers. Before text can be processed by a model, it must therefore be converted into a numerical representation.
The first step is tokenization, which splits text into smaller units called tokens. A token may represent a full word, part of a word, or a symbol. Each token is then transformed into a numerical vector known as an embedding.
Embeddings allow the model to represent the meaning of words within a multidimensional mathematical space. In this space, terms with similar meanings tend to appear close to each other. This allows the model to recognize linguistic relationships even when the exact same words are not used.
A visual representation of this principle can be observed in the TensorFlow Embedding Projector, a tool developed by Google to explore embeddings within vector space.
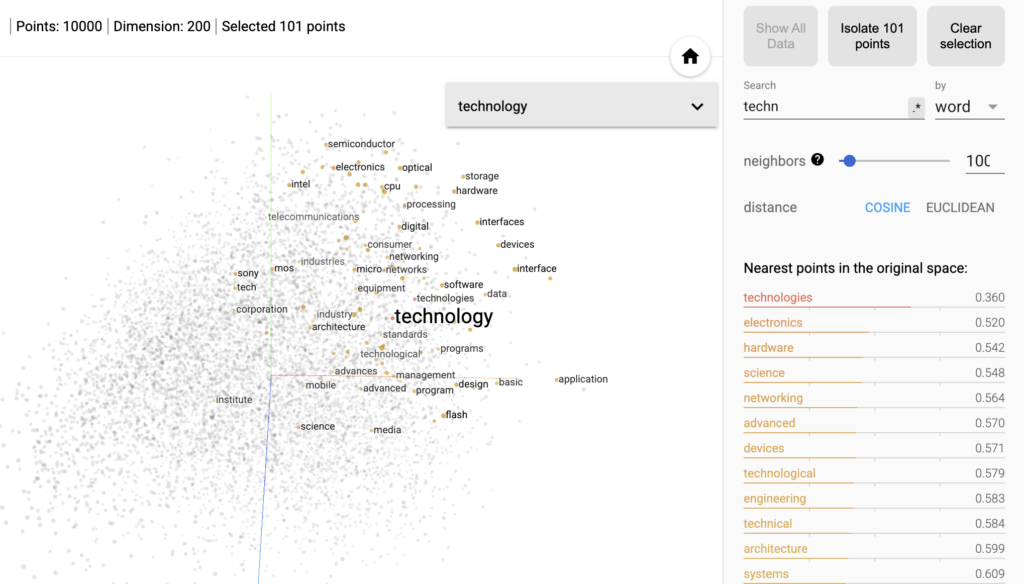
In these visualizations, each word is represented as a point: terms that share similar contexts or meanings tend to cluster close together. For example, searching for the word technology reveals nearby terms such as electronics, hardware, or engineering, showing how the model has learned semantic relationships between concepts.
_Pre-training and Fine-tuning
Building a Large Language Model typically involves two main phases.
During pre-training, the model is trained on massive amounts of data in order to learn the general structure of language.
A second phase, called fine-tuning, is then applied to adapt the model to specific tasks. This stage may include techniques such as instruction training or alignment through human feedback, which help improve the quality of responses and reduce undesirable behavior.
_The Main LLMs in 2026
In recent years, the landscape of Large Language Models has become extremely competitive. Different companies are developing models with distinct strategies: some focus on advanced reasoning capabilities, others on cloud scalability, while others emphasize open models that can run locally on different types of hardware.
For this reason, there is no single dominant model today, but rather an ecosystem of systems with different characteristics.
| Model | Company | Key Features |
|---|---|---|
| GPT-5 / GPT-5.4 | OpenAI | advanced reasoning, integrated AI agents, multimodality |
| Claude Opus 4.6 | Anthropic | adaptive thinking and complex planning |
| Gemini 3.1 Pro | Google DeepMind | extremely long context windows and advanced tool use |
| Llama 4 | Meta | open-weight models and native multimodality |
| Mistral Large 3 | Mistral AI | efficient Mixture-of-Experts architecture |
Although these models share the same technological foundation, the Transformer architecture, they differ in size, development strategy, and deployment model.
By size we refer to the number of parameters in the model, the internal variables that the neural network learns during training. Development strategy refers to how the model is designed and distributed, for example as a proprietary system accessed through APIs or as an open model that can be downloaded and customized. Finally, deployment model refers to the environment where the model runs: provider-managed cloud infrastructure or local, on-premise deployments on dedicated hardware.
Some models are designed primarily for large-scale cloud infrastructures, while others are intended to run locally or in environments that require greater control over data.
_LLMs in Enterprise Applications
Today, Large Language Models are becoming essential components of many enterprise systems.
One of the most common use cases is customer support, where LLMs enable the creation of assistance systems capable of understanding conversation context and providing consistent responses across multiple languages and based on internal company knowledge.
They are also transforming software development. More and more tools integrate language models directly into development environments, suggesting code modifications, completions, and even complex refactoring operations.
Another rapidly growing area is document analysis, where LLMs can summarize long reports, extract information from contracts, or analyze large volumes of textual data.
In many cases, these models do not replace existing systems but rather act as an intelligent interaction layer, enabling users to work with data and software directly through natural language.
_Current Limitations of LLMs
Despite their impressive progress, LLMs are not perfect systems, at least not yet.
One of the most well-known issues is the phenomenon of hallucinations, where models generate plausible but incorrect information. As we have seen, this happens because models do not truly “understand” the content of their responses but generate text based on probabilities learned during training. When they lack reliable information, they tend to fill the gaps by selecting words and concepts that are semantically close to the context, even if they are not factually correct.
There are also challenges related to bias in training data. The quality and reliability of training datasets play a crucial role in the development of language models, as discussed in our article on LLM brain rot and the quality of AI training data.
In addition, training and running the largest models requires extremely expensive computational infrastructure, both economically and in terms of energy consumption. For this reason, a significant part of current research focuses on developing more efficient models and new architectures capable of reducing costs while maintaining strong reasoning capabilities.
_Toward a New Generation of AI Systems
Large Language Models represent one of the foundational pillars of modern artificial intelligence. However, they are not the only technology transforming this field. In recent years, numerous specialized architectures have emerged to handle images, audio, graphs, and multimodal data. Many of the most advanced systems are beginning to combine these technologies to build increasingly sophisticated applications. Understanding how LLMs work is therefore the first step toward navigating an AI ecosystem that is evolving rapidly.
In the next articles of this series, we will explore other families of models that are expanding the capabilities of artificial intelligence far beyond language.


