
Which Humans? When Language Models Reflect Only One Cultural Framework
In September 2023, a group of researchers at the Harvard Kennedy School published a study titled Which Humans?. It poses a question that sounds simple yet powerful in the age of LLMs:
When we say that a language model thinks like a human being, which human are we talking about?
Today, as models evolve at an incredibly fast pace and find applications in every corner of business and tech consulting, the study remains surprisingly relevant. It’s a good moment to pause and reflect: How do we manage AI in global contexts? And how do we relate to an “artificial intelligence” that speaks with a specific cultural accent?
The authors’ answer is clear: these models resemble humans from so-called WEIRD societies (Western, Educated, Industrialized, Rich, Democratic). The further you move away from that profile, the less the model resembles an average human. A technical result, yes but one that immediately raises questions of tech culture: bias, representation, globality, ethics, and identity.
_How Do You Measure an Artificial Intelligence?
The authors treated OpenAI’s language model (GPT‑3.5/GPT‑4 via API) as if it were a human participant, administering questionnaires and cognitive tests and comparing the results with those of real people from different countries.
First Test: the World Values Survey
The WVS is one of the most comprehensive comparative databases that periodically collects data on values, beliefs, and attitudes across the globe.
It covers topics such as religion, fairness, trust in institutions, political participation, environment, family, and more. The study focused on data collected between 2017 and 2022, based on responses from 94,278 individuals across 65 countries.
To enable comparison, GPT was asked the same questions (1,000 responses per question) and the answers were analyzed using methods such as hierarchical clustering and multidimensional scaling, to see which countries GPT most resembled.
Second Test: the Triad Task
This cognitive test shows three items (e.g. “hair”, “beard”, “shampoo”) and asks to group two of them together. Choosing “beard–hair” (based on category) suggests a more analytical thinking style, while “hair–shampoo” (based on function/context) reflects a more relational/holistic cultural view.
This test was also given to the model, and again showed a strong similarity with WEIRD countries.
Third Test: Self-Concept Task
Lastly, the model was asked to write 10 sentences starting with “I am…”
Once again, GPT projected a vision of the “average human” that aligns closely with WEIRD cultures.In WEIRD societies, people are more likely to define themselves through individual attributes (“I am creative, athletic, etc.”), while in collectivist cultures, social roles and relationships emerge more strongly (“I am a son…, a member of…, etc.”).
For the Data Nerds
| Block | What It Measures | GPT Method | Human Comparison |
|---|---|---|---|
| WVS | Values, attitudes, trust, religion, politics, family, etc. | WVS questions via API; 1,000 samples per question; 262 variables analyzed | 94,278 people, 65 countries, representative samples (2017–2022) |
| Triad Task | Cognitive style: analytical (category) vs holistic (relationship) | 1,100 prompts on 20 triads, lightly reworded | 31 populations: known patterns (WEIRD ⇒ more analytical) |
| Self-Concept | “Who am I?”: individual attributes vs roles/relationships | Prompt: “List 10 ways a typical person defines themselves” | Compared with literature on WEIRD/non-WEIRD samples |
_An Iconic Result
When the researchers compared how similar GPT is to a country’s culture with that country’s cultural distance from the US, they found a strong inverse correlation (r = −0.70).
In simpler terms: the more culturally distant a country is from the USA, the less GPT resembles the answers given by that country’s population.
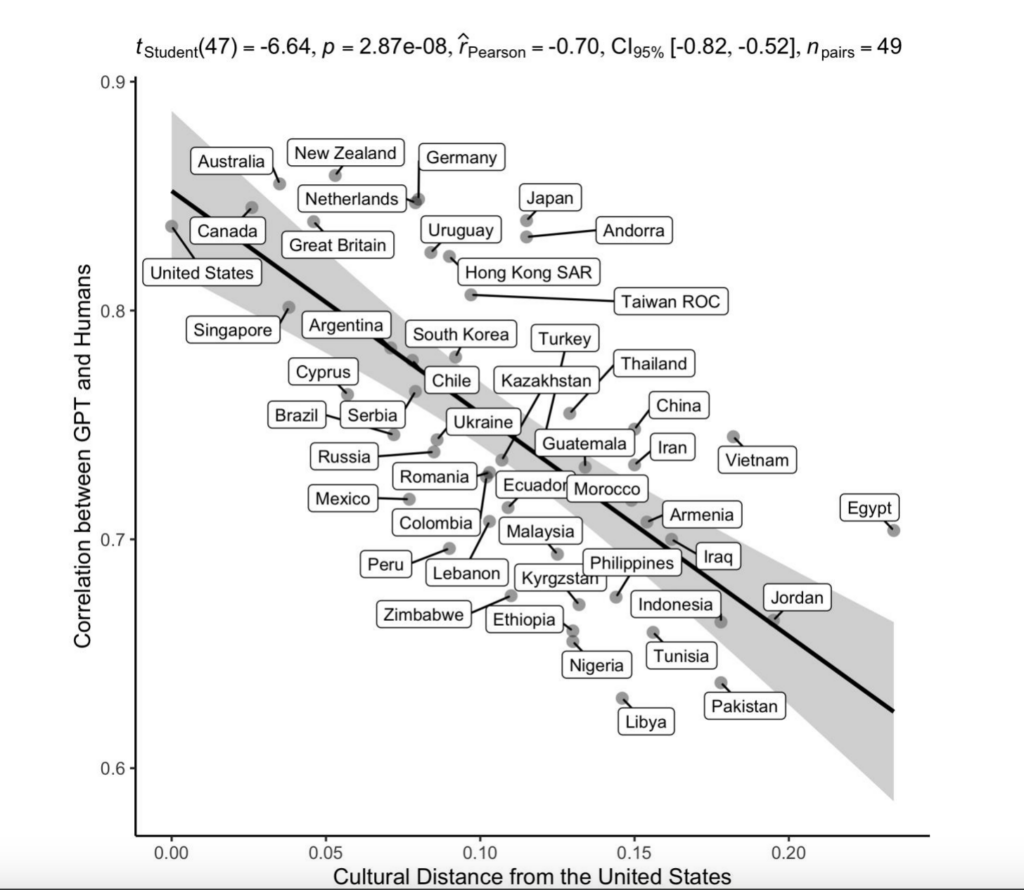
In addition to cultural distance, the researchers tested whether GPT–human similarity could also be influenced by development or digitalization levels.
They compared GPT similarity to a country with three socio-economic indicators:
| Indicator | Full Name | What It Measures | Observed Effect |
|---|---|---|---|
| HDI | Human Development Index | Combines income, education, and life expectancy (UN data) | Higher HDI → greater similarity with GPT |
| GDP per capita (log) | Gross Domestic Product per capita | Measures average economic wealth per person | Higher GDP → greater similarity |
| Internet Penetration | % of population with internet access | Measures connectivity and online presence | More internet → greater similarity |
Once again, the trend is clear: the more economically, educationally, and technologically developed a country is, the more it aligns with the model.
_When Data and Language Shape Thought
Modern language models are trained on massive textual datasets, but in a world where almost half the population lacks internet access, those datasets are built by and for users who are privileged in terms of access, education, and language. People who are connected, literate, and often English-speaking, a population that is structurally more WEIRD than the global average. And it’s not just about language. Each language, with its structures and categories, shapes how we formulate thoughts, build relationships, and express ideas.
When training data is written in a specific language and inside a dominant cultural context, the model inherits that cognitive imprint.
According to the study, models trained mostly on English-language content internalize patterns typical of WEIRD societies: individualism, generalized trust, abstract reasoning, role flexibility, and a lower emphasis on relational context.
⚠️ Important: A multilingual model is not necessarily a multicultural one.
Even if it can “speak Italian” or “answer in Spanish,” it may still think using the mental and cultural patterns of its original training dataset, often far from the cultural background of the user.
_Not so WEIRD: Italy and the Mediterranean
In the World Values Survey dataset, Italy emerges as a hybrid culture: Western and industrialized, but with strong relational components, such as family centrality, proximity networks, and social context, that are more prominent than in the US.
Italy appears as semi-WEIRD: close to Western countries, but with distinctive traits that combine secular/individualist elements with relational morality and context sensitivity typical of Mediterranean societies. This means that when we use language models like those examined in the study, we should be aware that:
- The “average human” profile assumed by the model does not fully match ours
- Essential nuances might be lost, such as the role of social context, the value of local networks, or the way trust is mediated through relationships
- Even in Italian, AI can appear more impersonal, more analytical, and more category-oriented than how an average Italian would respond
In practice, this means that even using a prompt in Italian, the model may reason according to analytical, individualist, and impersonal conceptual frameworks (e.g., generalized trust, low deference to authority, abstract classifications), sometimes misaligned with cultural nuances.
This can create an implicit cultural mismatch, especially in professional or decision-making contexts — far from a minor detail.
_Study Limitations and Ethical Dilemmas
No analysis is perfect, and the authors are clear about the study’s limitations.
It’s based on OpenAI models from 2023, does not cover all LLMs, and relies on training data that are not entirely transparent.
The comparison between humans and models remains metaphorical: LLMs have no body, context, or lived experience, and “speaking” a language doesn’t mean thinking like a native speaker.
In addition to these technical limits, the study raises key ethical issues:
- Partial Universalism: If models reflect WEIRD values, using them as the “voice of humanity” in research or policymaking risks excluding billions of people
- Cultural Moderation: Uniform safety rules may censor legitimate content in some cultures while ignoring inappropriate content in others
- Replacing Human Subjects: Using LLMs instead of real human samples in psychology or civic tech can result in distorted, unrepresentative data (models “know” WEIRD cultures well, but little about the rest)
_New Developments: Cultural Prompting
The Harvard study sparked interest, but didn’t remain isolated. Two more recent studies are worth noting:
In 2024, PNAS Nexus published Cultural bias and cultural alignment of large language models, analyzing five popular models (GPT‑3, GPT‑3.5, GPT‑4, GPT‑4o…) and comparing their behavior to national value datasets from over 100 countries. The result: all showed “Anglo-European/Protestant” values by default. But here’s the interesting part: adding the prompt “respond as a person from X culture” improved alignment in 71–81% of cases.
Another 2025 study, Toward accurate psychological simulations, found that LLMs tend to inflate positive traits (e.g., high extraversion) and reduce negative traits (e.g., psychopathy), resulting in an idealized version of the “average person.”
These new studies confirm and extend the findings of “Which Humans?”, showing that the problem isn’t solved, but there are operational levers (like cultural prompting) to reduce it. This means that choosing a powerful model isn’t enough. You must actively manage its implicit culture.
_What Technical and Strategic Solutions?
Let’s move from academic literature to everyday application. When building B2B IT solutions or training custom models, we can keep a few ideas in mind:
- In the dataset design phase: Add corpora from diverse languages and cultures — not just translations. Tokenizers and multilingual corpora aren’t enough: it matters who is in the data.
- In the fine-tuning/RLHF phase: Include multicultural annotators and quality rubrics that factor in cultural variables (e.g., cognitive style, relationality, context).
- In prompting and deployment: Enable “cultural context switching.” If the user is in Italy, add prompts like: “Answer as someone who lives in Italy and values group ties, family relationships, and local context.”
- Monitor cultural alignment: Define KPIs to measure model output against local benchmarks (like WVS or custom surveys).
_Conclusion
In our work with tech and consulting, we can see AI not only as a “tool” but also as a form of cultural mediation. If a model gives a “correct” answer, but from the mindset of an American graduate student, we need to ask: Is that the right fit for our client in Italy? Or for a company operating in Eastern Europe? Or the Middle East?
The study “Which Humans?” offers us a critical lens: AI is not (yet) universal, it is cultural, in the deepest sense. And if we want AI to elevate business, foster freedom, and spark creativity, we need to design it not just for power, but for cultural relevance. If we want AI to speak with the world, not instead of the world, we need to broaden the world we teach it.
And seriously measure whether it’s actually learning.





